



I. Prérequis▲
- Numpy (>= 1.2; de préférence plus récent…)
- Cython (>= 0.12, pour l'exemple de la Fonction Universelle)
- PIL (utilisé dans deux ou trois exemples)
Dans cette partie, Numpy sera importé comme suit :
>>> import numpy as npII. La vie d'un ndarray▲
II-A. C'est…▲
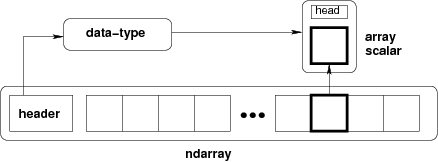
ndarray = bloc mémoire + schéma d'indexation + descripteur de type de données
- donnée brute
- comment localiser un élément
- comment interpréter un élément
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
typedef struct PyArrayObject {
PyObject_HEAD
/* Bloc de mémoire */
char *data;
/* Descripteur de type de données */
PyArray_Descr *descr;
/* Plan d'indexation */
int nd;
npy_intp *dimensions;
npy_intp *strides;
/* Autre chose */
PyObject *base;
int flags;
PyObject *weakreflist;
} PyArrayObject;
II-B. Bloc de mémoire▲
2.
3.
4.
5.
>>> x = np.array([1, 2, 3, 4], dtype=np.int32)
>>> x.data
<...at ...>
>>> str(x.data)
'\x01\x00\x00\x00\x02\x00\x00\x00\x03\x00\x00\x00\x04\x00\x00\x00'
Adresse mémoire de la donnée:
>>> x.__array_interface__['data'][0]
64803824L'interface complète _array_interface_ :
2.
3.
4.
5.
6.
7.
>>> x.__array_interface__
{'data': (35828928, False),
'descr': [('', '<i4')],
'shape': (4,),
'strides': None,
'typestr': '<i4',
'version': 3}
deux ndarrays peuvent partager la même adresse mémoire
2.
3.
4.
5.
>>> x = np.array([1, 2, 3, 4])
>>> y = x[:-1]
>>> x[0] = 9
>>> y
array([9, 2, 3])
L'adresse mémoire n'a pas besoin d'appartenir à un ndarray :
>>> x = b'1234'
#Le 'b' est pour « bytes », nécessaire en Python 3x est une chaîne de caractères (en Python 3, un « bytes »), nous pouvons le représenter comme un tableau d'entiers :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
>>> y = np.frombuffer(x, dtype=np.int8)
>>> y.data
<... at ...>
>>> y.base is x
True
>>> y.flags
C_CONTIGUOUS : True
F_CONTIGUOUS : True
OWNDATA : False
WRITEABLE : False
ALIGNED : True
UPDATEIFCOPY : False
Les indicateurs owndata et writeable précisent le statut du bloc mémoire.
II-C. Types de données▲
II-C-1. Le descripteur▲
dtype décrit un simple objet dans un tableau :
|
type |
Type scalaire des données, parmi: |
|
itemsize |
Taille du bloc de données |
|
byteorder |
Indicateur d'ordre des octets: big-endian > / little-endian < / non applicable | |
|
fields |
sub-dtypes, si c'est un type de données structurées |
|
shape |
Forme du tableau, si c'est un sous-tableau |
II-C-2. Exemple : lire les fichiers .wav ▲
L'entête du fichier .wav :
|
chunk_id |
"RIFF" |
|
chunk_size |
Nombre entier non signé à 4 octets au format little-endian |
|
format |
"WAVE" |
|
fmt_id |
"fmt " |
|
fmt_size |
Nombre entier non signé à 4 octets au format little-endian |
|
audio_fmt |
Nombre entier non signé à 2 octets au format little-endian |
|
num_channels |
Nombre entier non signé à 2 octets au format little-endian |
|
sample_rate |
Nombre entier non signé à 4 octets au format little-endian |
|
byte_rate |
Nombre entier non signé à 4 octets au format little-endian |
|
block_align |
Nombre entier non signé à 2 octets au format little-endian |
|
bits_per_sample |
Nombre entier non signé à 2 octets au format little-endian |
|
data_id |
"data" |
|
data_size |
Nombre entier non signé à 4 octets au format little-endian |
- bloc de données brutes à 44 octets (au début du fichier)
- … suivi par data_size d'octets de données réelles audio
L'entête du fichier .wav en tant que type de données structurées Numpy :
>>> wav_header_dtype = np.dtype([
... ("chunk_id", (bytes, 4)), # type scalaire à taille flexible, taille de l'objet 4
... ("chunk_size", "<u4"), # Nombre entier non signé à 32 bits au format little-endian
... ("format", "S4"), # chaîne de caractères à 4 octets
... ("fmt_id", "S4"),
... ("fmt_size", "<u4"),
... ("audio_fmt", "<u2"), #
... ("num_channels", "<u2"), # .. plus encore...
... ("sample_rate", "<u4"), #
... ("byte_rate", "<u4"),
... ("block_align", "<u2"),
... ("bits_per_sample", "<u2"),
... ("data_id", ("S1", (2, 2))), # sous-tableau, juste pour rire !
... ("data_size", "u4"),
... #
... # Les données du son lui-même ne peuvent pas être représentées ici:
... # ça n'a pas de taille fixe
... ])2.
3.
4.
5.
6.
>>> wav_header_dtype['format']
dtype('|S4')
>>> wav_header_dtype.fields
<dictproxy object at ...>
>>> wav_header_dtype.fields['format']
(dtype('|S4'), 8)
- Le premier élément est le « sub-dtype » dans les données structurées, correspondant au nom format
- Le deuxième élément est son décalage ( en octets) à partir du début de l'objet
Exercice
Faire un dtype « creux » en utilisant les décalages, et seulement quelques champs :
et l'utiliser pour lire la fréquence d'échantillonnage et data_id (en tant que sous-tableau).
2.
3.
4.
5.
6.
7.
>>> f = open('data/test.wav', 'r')
>>> wav_header = np.fromfile(f, dtype=wav_header_dtype, count=1)
>>> f.close()
>>> print(wav_header)
[ ('RIFF', 17402L, 'WAVE', 'fmt ', 16L, 1, 1, 16000L, 32000L, 2, 16, [['d', 'a'], ['t', 'a']], 17366L)]
>>> wav_header['sample_rate']
array([16000], dtype=uint32)
Essayons d'accéder au sous-tableau :
2.
3.
4.
5.
6.
7.
8.
>>> wav_header['data_id']
array([[['d', 'a'],
['t', 'a']]],
dtype='|S1')
>>> wav_header.shape
(1,)
>>> wav_header['data_id'].shape
(1, 2, 2)
Quand on accède aux sous-tableaux, les dimensions sont ajoutées à la fin!
Il existe des modules comme wavfile, audiolab, etc. pour charger des données audio.
II-C-3. Casting et réinterprétation/vues▲
Conversion de type
- sur attribution
- sur la construction d'un tableau
- sur l'arithmétique
- etc.
- et manuellement: .astype(dtype)
données réinterprétées
- manuellement: .view(dtype)
II-C-4. Conversion de types▲
-
En résumé, voici ce qu'il faut retenir du cast en arithmétique:
- seul le type (not value!) des opérandes nous intéresse
- le plus grand type « certifié » en mesure de représenter l'ensemble est considéré
- Les scalaires peuvent « perdre » face aux tableaux dans certaines situations
-
Le cast copie les données en général:
Sélectionnez1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.>>>x=np.array([1,2,3,4], dtype=np.float)>>>xarray([1.,2.,3.,4.])>>>y=x.astype(np.int8)>>>yarray([1,2,3,4], dtype=int8)>>>y+1array([2,3,4,5], dtype=int8)>>>y+256array([257,258,259,260], dtype=int16)>>>y+256.0array([257.,258.,259.,260.])>>>y+np.array([256], dtype=np.int32)array([257,258,259,260], dtype=int32) - Cast sur un objet setté : le « dtype » du tableau n'est pas modifié sur l'affectation d'un objet :
2.
3.
>>> y[:] = y + 1.5
>>> y
array([2, 3, 4, 5], dtype=int8)
II-C-4-a. Réinterprétation / Observation▲
-
Bloc de données en mémoire (4 octets)
0x01
||
0x02
||
0x03
||
0x04
-
4 entiers non signés uint8, ou,
-
4 entiers signés int8, ou,
-
2 entiers signés int16, ou,
-
1 entier signé int32, ou,
-
1 flottant float32, ou,
-
…
-
-
Comment passer de l'un à l'autre?
- Changer le « dtype »:
2.
3.
4.
5.
6.
>>> x = np.array([1, 2, 3, 4], dtype=np.uint8)
>>> x.dtype = "<i2"
>>> x
array([ 513, 1027], dtype=int16)
>>> 0x0201, 0x0403
(513, 1027)
|
0x01 |
0x02 |
|| |
0x03 |
0x04 |
Little-endian : l'octet le moins significatif est à gauche dans la mémoire
- Créer une nouvelle vue :
2.
3.
4.
5.
>>> y = x.view("<i4")
>>> y
array([67305985], dtype=int32)
>>> 0x04030201
67305985
|
0x01 |
0x02 |
0x03 |
0x04 |
Note
- .view crée des vues, il ne copie pas (ou n'altère pas) le bloc mémoire
- il ne change que le « dtype » (et ajuste la forme du tableau ):
2.
3.
4.
5.
>>> x[1] = 5
>>> y
array([328193], dtype=int32)
>>> y.base is x
True
Mini-exercice : réinterprétation des données
Vous avez des données RGBA dans un tableau:
>>> x = np.zeros((10, 10, 4), dtype=np.int8)
>>> x[:, :, 0] = 1
>>> x[:, :, 1] = 2
>>> x[:, :, 2] = 3
>>> x[:, :, 3] = 4où les trois dernières dimensions sont les canaux R, B, et G, puis alpha.
Comment faire un tableau structuré (10, 10) avec des champs nommés ‘r', ‘g', ‘b', ‘a' sans copier les données ?
>>> y = ...
>>> assert (y['r'] == 1).all()
>>> assert (y['g'] == 2).all()
>>> assert (y['b'] == 3).all()
>>> assert (y['a'] == 4).all()Solution
Un autre tableau qui prend exactement 4 octets de mémoire :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
>>> y = np.array([[1, 3], [2, 4]], dtype=np.uint8).transpose()
>>> x = y.copy()
>>> x
array([[1, 2],
[3, 4]], dtype=uint8)
>>> y
array([[1, 2],
[3, 4]], dtype=uint8)
>>> x.view(np.int16)
array([[ 513],
[1027]], dtype=int16)
>>> 0x0201, 0x0403
(513, 1027)
>>> y.view(np.int16)
array([[ 769, 1026]], dtype=int16)
- Que s'est-il passé ?
- … nous avons besoin de regarder ce que x[0,1] vaut réellement
>>> 0x0301, 0x0402
(769, 1026)II-D. Plan d'indexation : les strides▲
II-D-1. Point principal▲
La question :
2.
3.
4.
5.
>>> x = np.array([[1, 2, 3],
... [4, 5, 6],
... [7, 8, 9]], dtype=np.int8)
>>> str(x.data)
'\x01\x02\x03\x04\x05\x06\x07\x08\t'
À quel octet débute l'objet x[1,2] dans x.data ?
La réponse (dans Numpy) :
- strides: le nombre d'octets à franchir pour trouver le prochain élément
- 1 stride par dimension
2.
3.
4.
5.
6.
7.
>>> x.strides
(3, 1)
>>> byte_offset = 3*1 + 1*2 # to find x[1,2]
>>> x.flat[byte_offset]
6
>>> x[1, 2]
6
- Simple, flexible
II-D-1-a. Programmation en C et Fortran▲
2.
3.
4.
5.
6.
>>> x = np.array([[1, 2, 3],
... [4, 5, 6]], dtype=np.int16, order='C')
>>> x.strides
(6, 2)
>>> str(x.data)
'\x01\x00\x02\x00\x03\x00\x04\x00\x05\x00\x06\x00'
- Nécessité d'augmenter de 6 octets pour trouver la ligne suivante
- Nécessité d'augmenter de 2 octets pour trouver la colonne suivante
2.
3.
4.
5.
>>> y = np.array(x, order='F')
>>> y.strides
(2, 4)
>>> str(y.data)
'\x01\x00\x04\x00\x07\x00\x02\x00\x05\x00\x08\x00\x03\x00\x06\x00'
- Nécessité d'augmenter 2 octets pour trouver la ligne suivante
- Nécessité d'augmenter 4 octets pour trouver la colonne suivante
- De la même façon avec des dimensions supérieures
- C : les dernières dimensions varient plus vite (= strides plus petits)
- F : les premières dimensions varient plus vite
Maintenant nous pouvons comprendre le comportement de .view() :
>>> y = np.array([[1, 3], [2, 4]], dtype=np.uint8).transpose()
>>> x = y.copy()La transposition n'affecte pas la mise en mémoire des données, seulement les strides
- les résultats sont différents lorsque c'est interprété comme deux « int16 »
- .copy() crée de nouveaux tableaux comme en C (par défaut)
II-D-1-b. Partage avec des nombres entiers▲
- Tout peut être représenté en changeant seulement shape, stride, et en ajustant au besoin le pointeur data !
- Ne jamais faire de copie des données
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
>>> x = np.array([1, 2, 3, 4, 5, 6], dtype=np.int32)
>>> y = x[::-1]
>>> y
array([6, 5, 4, 3, 2, 1], dtype=int32)
>>> y.strides
(-4,)
>>> y = x[2:]
>>> y.__array_interface__['data'][0] - x.__array_interface__['data'][0]
8
>>> x = np.zeros((10, 10, 10), dtype=np.float)
>>> x.strides
(800, 80, 8)
>>> x[::2,::3,::4].strides
(1600, 240, 32)
De même, les transpositions ne créent jamais de copies (elles permutent juste les strides)
2.
3.
4.
5.
>>> x = np.zeros((10, 10, 10), dtype=np.float)
>>> x.strides
(800, 80, 8)
>>> x.T.strides
(8, 80, 800)
Mais toutes les opérations de redimensionnement de tableau ne peuvent être effectuées seulement en manipulant les strides :
2.
3.
4.
>>> a = np.arange(6, dtype=np.int8).reshape(3, 2)
>>> b = a.T
>>> b.strides
(1, 2)
Jusqu'ici tout va bien, toutefois :
2.
3.
4.
5.
6.
7.
8.
>>> str(a.data)
'\x00\x01\x02\x03\x04\x05'
>>> b
array([[0, 2, 4],
[1, 3, 5]], dtype=int8)
>>> c = b.reshape(3*2)
>>> c
array([0, 2, 4, 1, 3, 5], dtype=int8)
Ici, il n'y a aucun moyen de représenter le tableau c étant donné qu'il y a un stride et le bloc de mémoire pour a. Par conséquent, l'opération reshape a besoin d'en faire une copie.
II-D-2. Exemple : des dimensions faussées avec les strides▲
Manipulation d'un stride
2.
3.
4.
>>> from numpy.lib.stride_tricks import as_strided
>>> help(as_strided)
as_strided(x, shape=None, strides=None)
Fare un ndarray à partir du tableau avec les paramètres shape et strides fournis
as_strided ne vérifie pas que vous restez à l'intérieur des limites du bloc mémoire.
2.
3.
4.
5.
>>> x = np.array([1, 2, 3, 4], dtype=np.int16)
>>> as_strided(x, strides=(2*2, ), shape=(2, ))
array([1, 3], dtype=int16)
>>> x[::2]
array([1, 3], dtype=int16)
Exercice
2.
3.
4.
array([1, 2, 3, 4], dtype=np.int8)
-> array([[1, 2, 3, 4],
[1, 2, 3, 4],
[1, 2, 3, 4]], dtype=np.int8)
en utilisant seulement as_strided :
Hint: byte_offset = stride[0]*index[0] + stride[1]*index[1] + ...Solution
Stride peut aussi être 0
II-D-3. Diffusion (Broadcasting)▲
- Faisons quelque chose d'utile avec ça : produit externe de [1, 2, 3, 4] et [5, 6, 7]
2.
3.
4.
5.
6.
>>> x = np.array([1, 2, 3, 4], dtype=np.int16)
>>> x2 = as_strided(x, strides=(0, 1*2), shape=(3, 4))
>>> x2
array([[1, 2, 3, 4],
[1, 2, 3, 4],
[1, 2, 3, 4]], dtype=int16)
2.
3.
4.
5.
6.
>>> y = np.array([5, 6, 7], dtype=np.int16)
>>> y2 = as_strided(y, strides=(1*2, 0), shape=(3, 4))
>>> y2
array([[5, 5, 5, 5],
[6, 6, 6, 6],
[7, 7, 7, 7]], dtype=int16)
2.
3.
4.
>>> x2 * y2
array([[ 5, 10, 15, 20],
[ 6, 12, 18, 24],
[ 7, 14, 21, 28]], dtype=int16)
… semble quelque peu familier…
2.
3.
4.
5.
6.
>>> x = np.array([1, 2, 3, 4], dtype=np.int16)
>>> y = np.array([5, 6, 7], dtype=np.int16)
>>> x[np.newaxis,:] * y[:,np.newaxis]
array([[ 5, 10, 15, 20],
[ 6, 12, 18, 24],
[ 7, 14, 21, 28]], dtype=int16)
- En interne, le principe de diffusion de tableau est en effet implémenté en utilisant des 0-strides.
II-D-4. Plus de choses : diagonales▲
Défi
-
Extraire la diagonale principale de la matrice : (en supposant que la mémoire est ordonnée comme en C):
Sélectionnez1.
2.
3.
4.
5.>>>x=np.array([[1,2,3], ... [4,5,6], ... [7,8,9]], dtype=np.int32)>>>x_diag=as_strided(x, shape=(3,), strides=(???,)) -
Extraire les éléments de la première super-diagonale [2, 6].
- Et les sous-diagonales?
(Astuce pour les deux derniers points : le premier découpage déplace le point où le « striding » a commencé.)
Solution
Sélectionnez les diagonales:
Tranchez d'abord, pour ajuster le pointeur de données:
Note : Utilisation de np.diag
>>> y = np.diag(x, k=1)
>>> y
array([2, 6], dtype=int32)Cependant,
>>> y.flags.owndata
FalseRemarque : ce comportement a changé : avant numpy 1.9, np.diag en fait une copie.
Défi
Calculer la trace du tenseur :
en utilisant les strides et sum() sur le résultat.
>>> y = as_strided(x, shape=(5, 5), strides=(TODO, TODO))
>>> s2 = ...
>>> assert s == s2Solution
II-D-5. Les effets de cache du CPU▲
La mise en mémoire peut affecter les performances:
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
In [1]: x = np.zeros((20000,))
In [2]: y = np.zeros((20000*67,))[::67]
In [3]: x.shape, y.shape
((20000,), (20000,))
In [4]: %timeit x.sum()
100000 loops, best of 3: 0.180 ms per loop
In [5]: %timeit y.sum()
100000 loops, best of 3: 2.34 ms per loop
In [6]: x.strides, y.strides
((8,), (536,))
Les strides plus petits sont-ils plus rapides ?
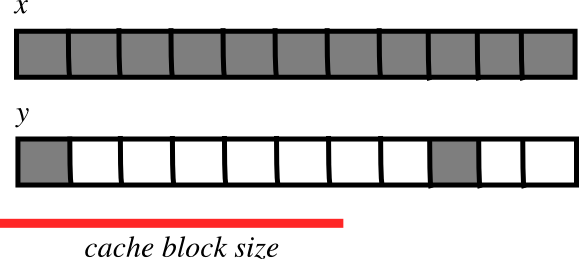
- Le CPU extrait des données de la mémoire principale à son cache en blocs
-
Si de nombreux éléments du tableau sont ajustés en un seul bloc (petit stride):
- moins de transferts nécessaires
- plus rapide
Voir aussi : numexpr est conçu pour atténuer les effets de cache sur les traitements de tableaux.
II-D-6. Exemple: les opérations en place (caveat emptor)▲
- Parfois,
>>> a -= bn'est pas pareil que :
>>> a -= b.copy()2.
3.
4.
5.
>>> x = np.array([[1, 2], [3, 4]])
>>> x -= x.transpose()
>>> x
array([[ 0, -1],
[ 4, 0]])
2.
3.
4.
5.
>>> y = np.array([[1, 2], [3, 4]])
>>> y -= y.T.copy()
>>> y
array([[ 0, -1],
[ 1, 0]])
- x et x.transpose() partagent les données
- x -= x.transpose() modifie les données élément par élément
- parce que x and x.transpose() ont un striding différent, des données modifiées réapparaissent sur le RHS
II-E. Conclusions en bref▲
- bloc mémoire : peut être partagé, .base, .data
- descripteur de type de données : données structurées, sous-tableaux, l'ordre des octets, cast, vues, .astype(), .view()
- indexation strided : les strides, programmation C-F, découpage w/ entiers, as_strided , diffusion, astuces sur le stride, diag , cohérence du cache du CPU
III. Les fonctions universelles▲
III-A. De quoi s'agit-il ?▲
- Les fonctions Ufunc (Universal functions) effectuent une opération élémentaire sur tous les éléments d'un tableau.
- Exemples:
np.add, np.subtract, scipy.special.*, ...- elles supportent automatiquement : la diffusion, le cast.
- L'auteur d'une ufunc n'a qu'à fournir l'opération par élément, Numpy s'occupe du reste.
- L'opération par élément nécessite d'être implémenté en C (ou par exemple , Cython)
III-A-1. Les parties d'une fonction Ufunc▲
-
Fournies par l'utilisateur
Sélectionnez1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.voidufunc_loop(void**args, int*dimensions, int*steps, void*data) {/**int8 output=elementwise_function(int8 input_1, int8 input_2)**Cette fonction doit calculer la ufunc pour plusieurs valeurs à la fois*de la manière suivante.*/char*input_1=(char*)args[0]; char*input_2=(char*)args[1]; char*output=(char*)args[2]; int i;for(i=0; i<dimensions[0];++i) {*output=elementwise_function(*input_1,*input_2); input_1+=steps[0]; input_2+=steps[1]; output+=steps[2]; } } -
La partie Numpy intégrée
Sélectionnez1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.char types[3] types[0]=NPY_BYTE/*type du premier argument en entrée*/types[1]=NPY_BYTE/*type du second argument en entrée*/types[2]=NPY_BYTE/*type du troisième argument en entrée*/PyObject*python_ufunc=PyUFunc_FromFuncAndData(ufunc_loop, NULL, types,1,/*ntypes*/2,/*num_inputs*/1,/*num_outputs*/identity_element, name, docstring, unused)- Une ufunc peut également prendre en charge plusieurs combinaisons différentes de type entrée-sortie.
III-A-2. Faciliter les choses▲
ufunc_loop est de forme très générique, et Numpy en fournit des préfabriquées
|
PyUfunc_f_f |
float elementwise_func(float input_1) |
|
PyUfunc_ff_f |
float elementwise_func(float input_1, float input_2) |
|
PyUfunc_d_d |
double elementwise_func(double input_1) |
|
PyUfunc_dd_d |
double elementwise_func(double input_1, double input_2) |
|
PyUfunc_D_D |
elementwise_func(npy_cdouble *input, npy_cdouble* output) |
|
PyUfunc_DD_D |
elementwise_func(npy_cdouble *in1, npy_cdouble *in2, npy_cdouble* out) |
- Seul elementwise_func doit être fourni
- … sauf si votre fonction par élément n'est pas dans l'une des formes ci-dessus.
III-B. Exercice : construire une ufunc à partir de zéro▲
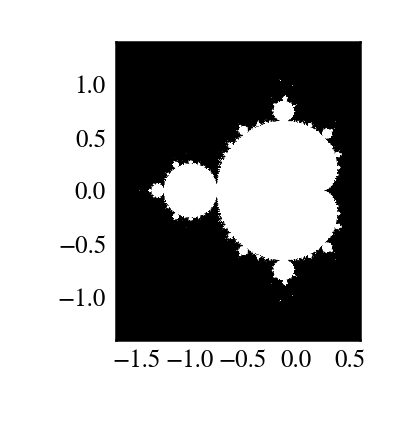
La fractale de Mandelbrot est définie par l'itération ![]() où
où ![]() est un nombre complexe. Cette itération est répétée - si
est un nombre complexe. Cette itération est répétée - si ![]() ne diverge pas, peu importe la durée du parcours des itérations,
ne diverge pas, peu importe la durée du parcours des itérations, ![]() appartient à l'ensemble de Mandelbrot.
appartient à l'ensemble de Mandelbrot.
-
Faire une ufunc appelée mandel(z0, c) qui calcule:
Sélectionnezz=z0forkinrange(iterations): z=z*z+cDisons 100 itérations ou bien jusqu'à ce que z.real**2 + z.imag**2 > 1000. Utilisez-la pour déterminer quels éléments c sont dans l'ensemble de Mandelbrot.
-
Notre fonction est simple, donc faire usage de l'aide de PyUFunc_*.
- L'écrire en Cython
Rappel : Quelques boucles ufunc préconstruites :
|
PyUfunc_f_f |
float elementwise_func(float input_1) |
|
PyUfunc_ff_f |
float elementwise_func(float input_1, float input_2) |
|
PyUfunc_d_d |
double elementwise_func(double input_1) |
|
PyUfunc_dd_d |
double elementwise_func(double input_1, double input_2) |
|
PyUfunc_D_D |
elementwise_func(complex_double *input, complex_double* output) |
|
PyUfunc_DD_D |
elementwise_func(complex_double *in1, complex_double *in2, compl ex_double* out) |
Codes types :
NPY_BOOL, NPY_BYTE, NPY_UBYTE, NPY_SHORT, NPY_USHORT, NPY_INT, NPY_UINT,
NPY_LONG, NPY_ULONG, NPY_LONGLONG, NPY_ULONGLONG, NPY_FLOAT, NPY_DOUBLE,
NPY_LONGDOUBLE, NPY_CFLOAT, NPY_CDOUBLE, NPY_CLONGDOUBLE, NPY_DATETIME,
NPY_TIMEDELTA, NPY_OBJECT, NPY_STRING, NPY_UNICODE, NPY_VOIDIII-C. Solution : construire une ufunc à partir de zéro▲
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
71.
72.
73.
74.
75.
76.
77.
78.
79.
80.
81.
82.
83.
84.
85.
86.
87.
88.
89.
90.
91.
92.
93.
94.
95.
96.
97.
98.
99.
100.
101.
102.
103.
104.
105.
106.
# La fonction par élément
# ------------------------
cdef void mandel_single_point(double complex *z_in,
double complex *c_in,
double complex *z_out) nogil:
#
# L'itération de Mandelbrot
#
#
# Quelques points:
#
# - Il n'est pas autorisé d'appeler n'importe qu'elles
# fonctions Python ici.
#
# La boucle Ufunc fonctionne avec le Python Global Interpreter Lock publié
# Par conséquent, le ``nogil``.
#
# - Et toutes les variables locales doivent être déclarées avec ''cdef''
#
# Notez également que cette fonction reçoit des *pointeurs* vers les données
# La solution « traditionnelle » pour passer des variables complexes autour
#
cdef double complex z = z_in[0]
cdef double complex c = c_in[0]
cdef int k # L'entier utilisé dans la boucle for
# Itération simple
for k in range(100):
z = z*z + c
if z.real**2 + z.imag**2 > 1000:
break
# Renvoie la réponse pour ce point
z_out[0] = z
# Définitions Boilerplate Cython
#
# Vous n'avez pas nécessairement besoin de lire cette partie, c'est simplement extrait des entêtes de Numpy C.
# ----------------------------------------------------------
cdef extern from "numpy/arrayobject.h":
void import_array()
ctypedef int npy_intp
cdef enum NPY_TYPES:
NPY_CDOUBLE
cdef extern from "numpy/ufuncobject.h":
void import_ufunc()
ctypedef void (*PyUFuncGenericFunction)(char**, npy_intp*, npy_intp*, void*)
object PyUFunc_FromFuncAndData(PyUFuncGenericFunction* func, void** data,
char* types, int ntypes, int nin, int nout,
int identity, char* name, char* doc, int c)
void PyUFunc_DD_D(char**, npy_intp*, npy_intp*, void*)
# module initialisation requis
# ------------------------------
import_array()
import_ufunc()
# La déclaration ufunc réelle
# ----------------------------
cdef PyUFuncGenericFunction loop_func[1]
cdef char input_output_types[3]
cdef void *elementwise_funcs[1]
loop_func[0] = PyUFunc_DD_D
input_output_types[0] = NPY_CDOUBLE
input_output_types[1] = NPY_CDOUBLE
input_output_types[2] = NPY_CDOUBLE
elementwise_funcs[0] = <void*>mandel_single_point
mandel = PyUFunc_FromFuncAndData(
loop_func,
elementwise_funcs,
input_output_types,
1, # nombre de type d'entrées supportées
2, # nombre d'arguments en entrée
1, # nombre d'arguments en sortie
0, # élément `identity`, ne vous en occupez jamais
"mandel", # nom de fonction
"mandel(z, c) -> computes iterated z*z + c", # docstring
0 # inutilisé
)
import numpy as np
import mandel
x = np.linspace(-1.7, 0.6, 1000)
y = np.linspace(-1.4, 1.4, 1000)
c = x[None,:] + 1j*y[:,None]
z = mandel.mandel(c, c)
import matplotlib.pyplot as plt
plt.imshow(abs(z)**2 < 1000, extent=[-1.7, 0.6, -1.4, 1.4])
plt.gray()
plt.show()
La plupart des outils pourraient être automatisés par ces modules Cython.
Plusieurs types d'entrées acceptés
Par exemple supportant les versions à simple et double précision
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
cdef void mandel_single_point(double complex *z_in,
double complex *c_in,
double complex *z_out) nogil:
...
cdef void mandel_single_point_singleprec(float complex *z_in,
float complex *c_in,
float complex *z_out) nogil:
...
cdef PyUFuncGenericFunction loop_funcs[2]
cdef char input_output_types[3*2]
cdef void *elementwise_funcs[1*2]
loop_funcs[0] = PyUFunc_DD_D
input_output_types[0] = NPY_CDOUBLE
input_output_types[1] = NPY_CDOUBLE
input_output_types[2] = NPY_CDOUBLE
elementwise_funcs[0] = <void*>mandel_single_point
loop_funcs[1] = PyUFunc_FF_F
input_output_types[3] = NPY_CFLOAT
input_output_types[4] = NPY_CFLOAT
input_output_types[5] = NPY_CFLOAT
elementwise_funcs[1] = <void*>mandel_single_point_singleprec
mandel = PyUFunc_FromFuncAndData(
loop_func,
elementwise_funcs,
input_output_types,
2, # nombre de types d'entrées supportées <-------------
2, # nombre d'arguments en entrée
1, # nombre d'arguments en sortie
0, # élément `identity`, ne vous en occupez jamais
"mandel", # nom de fonction
"mandel(z, c) -> computes iterated z*z + c", # docstring
0 # inutilisé
)
III-D. ufuncs généralisées▲
ufunc
output = elementwise_function(output)
output et input peuvent être tous les deux un élément d'un tableau
ufunc généralisée
output et input peuvent être des tableaux avec un nombre de dimensions fixe.
Par exemple, la matrice de trace (somme des éléments diagonaux)
2.
3.
4.
input shape = (n, n)
output shape = () i.e. scalar
(n, n) -> ()
Produit matriciel :
2.
3.
4.
5.
input_1 shape = (m, n)
input_2 shape = (n, p)
output shape = (m, p)
(m, n), (n, p) -> (m, p)
- Ceci est appelé la « signature » de la fonction ufunc généralisée
- Les dimensions sur lesquelles le g-ufunc agit, sont des « dimensions fondamentales »
Statuts dans Numpy
- g-ufuncs sont déjà en Numpy …
- Les nouvelles peuvent être créées avec PyUFunc_FromFuncAndDataAndSignature
- … Mais nous ne livrons pas avec des g-ufuncs publiques, sauf pour les tests, ATM
2.
3.
>>> import numpy.core.umath_tests as ut
>>> ut.matrix_multiply.signature
'(m,n),(n,p)->(m,p)'
>>> x = np.ones((10, 2, 4))
>>> y = np.ones((10, 4, 5))
>>> ut.matrix_multiply(x, y).shape
(10, 2, 5)- Les deux dernières dimensions sont devenues des dimensions fondamentales, et sont modifiées tout comme la signature
- Par ailleurs, la g-func fonctionne « par élément »
- La multiplication matricielle pourrait de cette façon être utile pour fonctionner sur de nombreuses petites matrices à la fois.
Boucle ufunc généralisée
Multiplication matricielle (m,n),(n,p) -> (m,p)
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
void gufunc_loop(void **args, int *dimensions, int *steps, void *data)
{
char *input_1 = (char*)args[0]; /* idem que précédemment */
char *input_2 = (char*)args[1];
char *output = (char*)args[2];
int input_1_stride_m = steps[3]; /* Les strides pour les dimensions fondamentales*/
int input_1_stride_n = steps[4]; /* sont ajoutés après la partie non-fondamentale */
int input_2_strides_n = steps[5]; /* étapes */
int input_2_strides_p = steps[6];
int output_strides_n = steps[7];
int output_strides_p = steps[8];
int m = dimension[1]; /* les dimensions fondamentales sont ajoutées après */
int n = dimension[2]; /* la dimension principale */
int p = dimension[3]; /* signature */
int i;
for (i = 0; i < dimensions[0]; ++i) {
matmul_for_strided_matrices(input_1, input_2, output,
strides for each array...);
input_1 += steps[0];
input_2 += steps[1];
output += steps[2];
}
}
IV. Les caractéristiques d'interopérabilité▲
IV-A. Partager des données multidimensionnelles, typées▲
Supposons que vous :
- Écriviez une bibliothèque qui gère des données binaires multidimensionnelles,
- Vous vouliez faciliter la manipulation des données avec Numpy, ou une tout autre bibliothèque,
- … mais que vous ne vouliez pas avoir Numpy comme dépendance.
Actuellement, trois solutions :
- la “vieille” interface tampon
- l'interface réseau
- la “nouvelle” interface tampon ( PEP 3118 )
IV-B. Le vieux protocole tampon▲
- Uniquement des tampons 1-D
- Pas d'information concernant le type de données
- Interface C-level ; PyBufferProcs tp_as_buffer dans l'objet type
- Mais c'est intégré dans Python (par exemple les chaînes de caractères le supportent)
Miniexercice utilisant PIL (Python Imaging Library):
2.
3.
4.
5.
6.
7.
>>> from PIL import Image
>>> data = np.zeros((200, 200, 4), dtype=np.int8)
>>> data[:, :] = [255, 0, 0, 255] # Red
>>> # Dans PIL, les images RGBA consistent en des entiers de 32-bit dont les octets sont [RR,GG,BB,AA]
>>> data = data.view(np.int32).squeeze()
>>> img = Image.frombuffer("RGBA", (200, 200), data)
>>> img.save('test.png')
Q: Vérifiez si les données sont à présent modifiées, et que l'img soit encore sauvegardée.
IV-C. L'ancien protocole tampon▲
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
" "
De la mémoire tampon
============
Montrer comment échanger des données entre numpy et une bibliothèque qui ne connaît que l'interface tampon.
import numpy as np
import Image
# faisons une image simple, au format RGBA
x = np.zeros((200, 200, 4), dtype=np.int8)
x[:,:,0] = 254 # rouge
x[:,:,3] = 255 # opaque
data = x.view(np.int32) # Vérifiez que vous comprenez pourquoi cela est OK !
img = Image.frombuffer("RGBA", (200, 200), data)
img.save('test.png')
#
# Modifiez les données d'origine, et enregistrez à nouveau
#
# Il se trouve que PIL, qui ne connaît presque rien sur Numpy,
# partage heureusement les mêmes données
#
x[:,:,1] = 254
img.save('test2.png')
|
|
|


IV-D. Protocole d'interface réseau▲
- Tampons multidimensionnels
- Présence d'information pour chaque type de données
- Approche spécifique Numpy; lentement déprécié (mais ne va pas disparaître)
- Non intégré dans Python autrement
- Voir aussi : Documentation: http://docs.scipy.org/doc/numpy/reference/arrays.interface.html
2.
3.
4.
5.
6.
7.
8.
9.
>>> x = np.array([[1, 2], [3, 4]])
>>> x.__array_interface__
{'data': (171694552, False), # adresse mémoire de la donnée, en lecture seule ?
'descr': [('', '<i4')], # descripteur du type de donnée
'typestr': '<i4', # idem, dans une autre forme
'strides': None, # strides; ou rien si c'est du C
'shape': (2, 2),
'version': 3,
}
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
>>> import Image
>>> img = Image.open('data/test.png')
>>> img.__array_interface__
{'data': ...,
'shape': (200, 200, 4),
'typestr': '|u1'}
>>> x = np.asarray(img)
>>> x.shape
(200, 200, 4)
>>> x.dtype
dtype('uint8')
Note : Une variante proche du C de l'interface réseau est également définie
V. Les tableaux fraternels : chararray, maskedarray, matrice▲
V-A. Chararray : opérations de chaînes de caractères vectorisées▲
2.
3.
4.
5.
6.
7.
>>> x = np.array(['a', ' bbb', ' ccc']).view(np.chararray)
>>> x.lstrip(' ')
chararray(['a', 'bbb', 'ccc'],
dtype='|S5')
>>> x.upper()
chararray(['A', ' BBB', ' CCC'],
dtype='|S5')
.view() a un autre sens : il peut faire d'un ndarray une instance d'une sous-classe d'un ndarray spécialisé
V-B. Données manquantes masked_array▲
Les tableaux masqués sont des tableaux qui peuvent avoir des entrées manquantes ou invalides. Par exemple, supposons que nous ayons un tableau où la quatrième entrée est invalide :
>>> x = np.array([1, 2, 3, -99, 5])Une façon de décrire cela est de créer un tableau masqué
2.
3.
4.
5.
>>> mx = np.ma.masked_array(x, mask=[0, 0, 0, 1, 0])
>>> mx
masked_array(data = [1 2 3 -- 5],
mask = [False False False True False],
fill_value = 999999)
Le mean masqué ignore les données masquées
>>> mx.mean()
2.75
>>> np.mean(mx)
2.75Toutes les fonctions Numpy ne respectent pas les masques, par exemple np.dot, donc vérifier les types de retour
Le masked_array renvoie une vue au tableau d'origine :
>>> mx[1] = 9
>>> x
array([ 1, 9, 3, -99, 5])V-B-1. Le masque▲
Vous pouvez modifier le masque par assignation :
2.
3.
4.
5.
>>> mx[1] = np.ma.masked
>>> mx
masked_array(data = [1 -- 3 -- 5],
mask = [False True False True False],
fill_value = 999999)
Le masque est ainsi effacé :
2.
3.
4.
5.
>>> mx[1] = 9
>>> mx
masked_array(data = [1 9 3 -- 5],
mask = [False False False True False],
fill_value = 999999)
Le masque est également disponible directement :
>>> mx.mask
array([False, False, False, True, False], dtype=bool)Les entrées masquées peuvent être remplies avec une valeur déterminée pour obtenir un tableau en retour :
2.
3.
>>> x2 = mx.filled(-1)
>>> x2
array([ 1, 9, 3, -1, 5])
Le masque peut aussi être effacé
2.
3.
4.
5.
>>> mx.mask = np.ma.nomask
>>> mx
masked_array(data = [1 9 3 -99 5],
mask = [False False False False False],
fill_value = 999999)
V-B-2. Fonctions du domaine-courant▲
Le package de tableau masqué contient également des fonctions de domaine-courant :
2.
3.
4.
>>> np.ma.log(np.array([1, 2, -1, -2, 3, -5]))
masked_array(data = [0.0 0.69314718056 -- -- 1.09861228867 --],
mask = [False False True True False True],
fill_value = 1e+20)
La Prise en charge simplifiée est plus transparente pour traiter les données manquantes dans les tableaux dans Numpy 1.7. Restez à l'écoute !
Exemple : Statistiques masquées
Des rangers canadiens ont été distraits lors du comptage de lièvres et de lynx en 1903-1910 et 1917-1918, et ont obtenu des chiffres incorrects. (Des cultivateurs de carottes sont restés en alerte, cependant.) Calculez les populations moyennes au fil du temps, en ignorant les chiffres invalides.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
>>> data = np.loadtxt('data/populations.txt')
>>> populations = np.ma.masked_array(data[:,1:])
>>> year = data[:, 0]
>>> bad_years = (((year >= 1903) & (year <= 1910))
... | ((year >= 1917) & (year <= 1918)))
>>> # '&' signifie 'and' et '|' signifie 'or'
>>> populations[bad_years, 0] = np.ma.masked
>>> populations[bad_years, 1] = np.ma.masked
>>> populations.mean(axis=0)
masked_array(data = [40472.7272727 18627.2727273 42400.0],
mask = [False False False],
fill_value = 1e+20)
>>> populations.std(axis=0)
masked_array(data = [21087.656489 15625.7998142 3322.50622558],
mask = [False False False],
fill_value = 1e+20)
Notez que Matplotlib connaît les tableaux masqués.
>>> plt.plot(year, populations, 'o-')
[<matplotlib.lines.Line2D object at ...>, ...]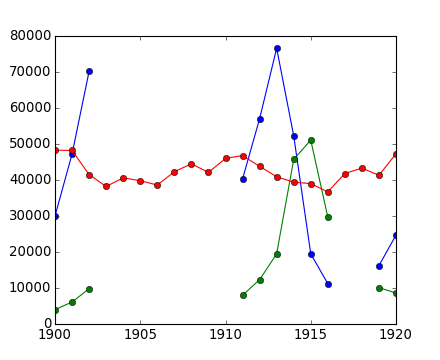
V-C. Recarray : par pure convenance▲
2.
3.
4.
5.
6.
7.
>>> arr = np.array([('a', 1), ('b', 2)], dtype=[('x', 'S1'), ('y', int)])
>>> arr2 = arr.view(np.recarray)
>>> arr2.x
chararray(['a', 'b'],
dtype='|S1')
>>> arr2.y
array([1, 2])
V-D. Matrix : convenance ?▲
- Toujours en 2D
- * est le produit matriciel, et non la matrice par élément
>>> np.matrix([[1, 0], [0, 1]]) * np.matrix([[1, 2], [3, 4]])
matrix([[1, 2],
[3, 4]])VI. En résumé▲
- Structure des ndarray : données, dtypes, strides.
- Fonctions universelles: opérations par élément, comment faire pour en créer une ?
- Sous-classes ndarray
- Différentes interfaces de tampons pour l'intégration avec d'autres outils
- Ajouts récents : PEP 3118, ufuncs généralisées
VII. Contribuer à Numpy/Scipy▲
Récupérez ce tutoriel: http://www.euroscipy.org/talk/882
VII-A. pourquoi▲
- Pour signaler un bogue
- Pour mieux comprendre
- Pour obtenir un code de qualité
- Pour apporter son aide
VII-B. rapporter les erreurs▲
-
Bug tracker (préférez cela)
- http://www.numpy.org/
- https://scipy.org/scipylib/index.html
- Cliquez sur le lien “S'inscrire” pour obtenir un compte
-
listes de diffusion ( scipy.org/Mailing_Lists )
- Si vous n'êtes pas sûr
- Aucune réponse au bout d'une semaine ou deux? Déposez juste un ticket d'erreur
VII-B-1. Exemple d'un bon rapport de bogue▲
Titre : numpy.random.permutations échoue pour des arguments de type non entier
Je suis en train de générer des permutations aléatoires, en utilisant numpy.random.permutations
Lors de l'appel de numpy.random.permutation avec des arguments non entiers.
Cela échoue avec un message d'erreur sibyllin :
>>> np.random.permutation(12)
array([ 6, 11, 4, 10, 2, 8, 1, 7, 9, 3, 0, 5])
>>> np.random.permutation(12.)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "mtrand.pyx", line 3311, in mtrand.RandomState.permutation
File "mtrand.pyx", line 3254, in mtrand.RandomState.shuffle
TypeError: len() of unsized objectCela se produit aussi avec des arguments de type long, et donc
np.random.permutation(X.shape[0]) où X est un tableau qui échoue sur Windows 64-bits(où la forme est un tuple de longs).
Ce serait génial si ça pouvait caster en entier ou au moins lever une erreur spécifique pour des types non entiers.
Je suis en train d'utiliser Numpy 1.4.1, construit à partir de l'archive officielle, sur Windows
64 avec Visual studio 2008, sur Python.org 64-bit Python.
- Qu'êtes-vous en train de faire?
-
Extrait de code reproduisant l'erreur (si possible)
- Que se passe-t-il réellement ?
- Qu'est-ce que vous attendez ?
- Plate-forme(Windows / Linux / OSX, 32/64 bits, x86/PPC…)
-
Version de Numpy/Scipy
Sélectionnez>>>printnp.__version__2... -
Vérifiez que ce qui suit est ce que vous aviez prévu :
Sélectionnez>>>printnp.__file__/... - Dans le cas où vous traîniez de vieilles installations de Numpy ou endommagées.
En cas de doute, essayez de supprimer les installations existantes de Numpy, puis réinstallez…